В этом посте мы рассмотрим детали колонок свойств (feature columns). Колонки свойств можно рассматривать как промежуточное звено между сырыми данными и Estimators. Колонки свойств имеют обширную функциональность и позволяют преобразовывать большой список различных сырых данных в форматы, которые могут использовать Estimators, предоставляя таким образом простор для экспериментов.
Среди предсозданных Estimators мы будем использовать tf.estimator.DNNClassifier для тренировки модели прогнозировать различные виды цветов ириса по четырем вводным свойствам. В этом примере создаются только числовые колонки свойств (тип tf.feature_column.numeric_column). Хотя числовые колонки свойств модели измеряют лепестки и чашелистики эффективно, в реальных данных наборы содержат все виды свойств, многие из которых нечисловые.

Некоторые свойства из реальных данных числовые (такие как, долгота), но многие нет.
Ввод в глубокую нейронную сеть
На каком типе данных может оперировать глубокая нейронная сеть? Ответ - числа (например, tf.float32). Каждый нейрон в нейронной сети выполняет операции умножения и сложения с весами и вводными данными. Вводные данные из реальной жизни, однако, часто содержат нечисловые (категориальные) значения. Например, предположим свойство product_class, который может содержать следующие три нечисловые значения:
- kitchenware
- electronics
- sports
Модели машинного обучения в основном представляют категориальные значения как простые вектора, в которых 1 представляет присутствие значения, а 0 означает отсуствие значения. Например, когда product_class установлен в sports, модель машинного обучения представляет product_class как [0, 0, 1], что означает:
- 0: kitchenware
- 0: electronics
- 1: sports
Таким образом, хотя сырые данные могут быть числовыми или категориальными, модель машинного обучения представляет все свойства как числа.
Колонки свойств (Feature Columns)
Как показано на следующем графике, ввод данных в модель определяется через feature_columns аргумент Estimator'а (DNNClassifier для ирисов). Колонки свойств (feature columns) - это мост между вводными данными (которые возвращает input_fn) и моделью.

Колонки свойств создают мост между сырыми данными и данными, которые требуются модели.
Для создания колонок свойств необходимо вызвать функции из tf.feature_column модуля. В этом посте мы затронем 9 функций из этого модуля. Как показано на следующей иллюстрации, все 9 функций возвращают либо Categorical Column, либо Dense Column объект, исключая bucketized_column, который наследуется из обоих этих классов:

Методы колонок свойств делятся на две категории и одну гибридную категорию.
Рассмотрим эти функции более детально.
Числовая колонка
Классификатор ирисов вызывает tf.feature_column.numeric_column функцию для всех вводных свойств:
- SepalLength
- SepalWidth
- PetalLength
- PetalWidth
Хотя для tf.numeric_column доступны опциональные аргументы, вызов tf.numeric_column без аргументов, как показано ниже, это отличный способ определить числовое значение с типом данных по умолчанию (tf.float32) как ввод для модели:
# По умолчанию tf.float32 scalar.
numeric_feature_column = tf.feature_column.numeric_column(
key="SepalLength")
Чтобы определить числовой тип данных не по умолчанию, используйте dtype аргумент. Например:
# Предаставляет tf.float64 scalar.
numeric_feature_column = tf.feature_column.numeric_column(
key="SepalLength",
dtype=tf.float64)
По умолчанию числовая колонка создает единственное значение (скаляр). Используйте shape аргумент, чтобы определить другую форму. Например:
# Представляем 10-элементный вектор,
# в котором каждая ячейка содержит tf.float32.
vector_feature_column = tf.feature_column.numeric_column(key="Bowling",
shape=10)
# Представляем 10x5 матрицу, в которой каждая ячейка содержит tf.float32
matrix_feature_column = tf.feature_column.numeric_column(key="MyMatrix",
shape=[10,5])
Пакетная колонка (Bucketized column)
Часто нет желания отправлять отдельное число напрямую в модель, вместо этого можно использовать пакетизацию и разделить значения на различные категории на основе числовых диапазонов. Чтобы выполнить это, создайте tf.feature_column.bucketized_column. Например, предположим сырые данные, представляющие год, в котором был построен дом. Вместо представления этого года как отдельной числовой колонки, разделим года на следующие четыре пакета:

Разделение данных по годам на четыре пакета.
Модель будет представлять пакеты следующим образом:

Почему мы разделили числа на категориальные значения, хотя простое число - это абсолютно валидный ввод для модели? Отметим, что категоризация разделяет единственное вводное число в четырехэлементный вектор. Поэтому модель теперь может обучаться четырем индивидуальным весам, а не просто одному. Четыре веса создают более богатую модель, чем один вес. Что более важно, пакетизация позволяет модели четко разделять различные годовые категории, даже если задан только один элемент, а остальные пустые. Например, когда мы используем просто единичное число как ввод, линейная модель может обучиться только линейным отношениям. Пакетизация предоставляет модели дополнительную гибкость, которую модель может использовать при обучении.
Следующий код демонстрирует как создать пакетизированное свойство:
# Во-первых, конвертируем сырой ввод в числовую колонку.
numeric_feature_column = tf.feature_column.numeric_column("Year")
# Затем пакетизируем числовую колонку по годам 1960, 1980, и 2000.
bucketized_feature_column = tf.feature_column.bucketized_column(
source_column = numeric_feature_column,
boundaries = [1960, 1980, 2000])
Отметим, что определение вектора по границам из трех элементов создает четырех-элементный пакетизированный вектор.
Категориальная индивидуальная колонка (Categorical identity column)
Категориальные индивидуальные колонки могут быть рассмотрены как специальный случай пакетизированных колонок. В традиционных пакетизированных колонках каждый пакет представляет диапазон значений (например, от 1960 до 1979). В категриальной индивидуальной колонке каждый пакет представляет единственное уникальное целое число. Например, представим числовой диапазон [0,4]. То есть представим числа 0, 1, 2, или 3. В этом случае, категориальное индивидуальное картирование выглядит следующим образом:

Картирование категориальной индивидуальной колонки. Следует отметить, что это одноразовое кодирование, не бинарное числовое кодирование.
Как и с пакетизированными клонками, модель может обучаться отдельному весу для каждого класса в категориальной индивидуальной колонке. Например, вместо использования строки для представления product_class, представим каждый класс уникальным числовым значением.
- 0="kitchenware"
- 1="electronics"
- 2="sport"
Вызываем tf.feature_column.categorical_column_with_identity для создания категориальной индивидуальной колонки. Например:
# Создаем категориальный вывод
# для числового свойства с именем "my_feature_b",
# значения my_feature_b должны быть >= 0 и < num_buckets
identity_feature_column = \
tf.feature_column.categorical_column_with_identity(
key='my_feature_b',
num_buckets=4) # Значения [0, 4]
# Для того чтобы предыдущий вызов заработал,
# input_fn() должна возвращать словарь,
# содержащий 'my_feature_b' в качестве ключа. Более того, значения,
# присвоенные к 'my_feature_b', должны быть от 0 до 4.
def input_fn():
...
return ({ 'my_feature_a':[7, 9, 5, 2],
'my_feature_b':[3, 1, 2, 2] },
[Label_values])
Категориальная словарная колонка (Categorical vocabulary column)
Мы не можем вводить строки напрямую в модель. Вместо этого, сначала мы должны картировать строки на числовые или категориальные значения. Категориальные словарные колонки предоставляют удобный способ представить строку как одноразовый вектор. Например:
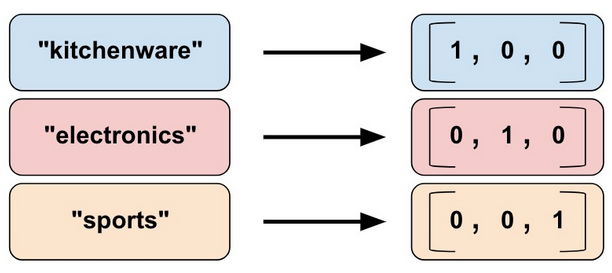
Картирование строковых значений в словарные колонки.
Как видно, категориальные словарные колонки - это enum версия категориальных индивидуальных колонок. TensorFlow предоставляет две функции для создания категориальных словарных колонок:
- tf.feature_column.categorical_column_with_vocabulary_list
- tf.feature_column.categorical_column_with_vocabulary_file
categorical_column_with_vocabulary_list картирует каждую строку к числу, основываясь на явно заданном словарном списке. Например:
# Дан ввод "feature_name_from_input_fn" являющийся строкой,
# создаем категориальное свойство, картируя ввод
# к одному из элементов в словарном списке.
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_list(
key=feature_name_from_input_fn,
vocabulary_list=["kitchenware", "electronics", "sports"])
Предыдущая функция простая и ясная, но имеет значительный недостаток. А именно, необходимо слишком много печатать, когда словарный лист достаточно длинный. Для этих случаев вызываем метод tf.feature_column.categorical_column_with_vocabulary_file, который позволяет размещать словарные слова в отдельном файле. Например:
# Дан ввод "feature_name_from_input_fn" являющийся строкой,
# создаем категориальное свойство для нашей модели, картируя ввод
# к одному из элементов в словарном файле
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_file(
key=feature_name_from_input_fn,
vocabulary_file="product_class.txt",
vocabulary_size=3)
product_class.txt должен содержать по одной строке для каждого словарного элемента. В нашем случае:
kitchenware
electronics
sports
Хэшированная колонка (Hashed Column)
До сих пор мы работали с очень малым количеством категорий. Например, наш product_class пример имеет всего лишь 3 категории. Однако, зачастую количество категорий может быть настолько большим, что невозможно иметь индивидуальные категории для каждого словарного слова или числа, посколько это потребует слишком большого количества памяти. Для этих случаев можно взглянуть на проблему с другой стороны и задать себе вопрос: "Сколько категорий мне необходимо для моего ввода?" На деле tf.feature_column.categorical_column_with_hash_bucket функция позволяет определить такое количество категорий. Для этого типа колонки свойств модель высчитывает значение хэша для ввода и затем складывает его в одну из hash_bucket_size категорий, используя modulo оператор, как в следующем псевдокоде:
# pseudocode
feature_id = hash(raw_feature) % hash_bucket_size
Код создания feature_column может выглядеть следующим образом:
hashed_feature_column =
tf.feature_column.categorical_column_with_hash_bucket(
key = "some_feature",
hash_bucket_size = 100) # количество категорий
Мы переводим различные значения ввода в меньший набор категорий. Это означает, что два вероятно не связанных ввода будут картированы к одной и той же категории, и следовательно означать одну и ту же категорию в нейронной сети. Следующая иллюстрация показывает такую ситуацию, kitchenware и sports оба назначены к категории 12 (хэш пакет):

Представление данных с хэш пакетами.
Как и с многими непонятными феноменами в машинном обучении, оказывается, что хэширование часто хорошо работает на практике. Это потому что хэш категории предоставляют модели некоторое разделение. Модель может использовать дополнительные свойства для дальнейшего разделения kitchenware от sports.
Пересеченная колонка (Crossed column)
Комбинирование свойств в единственное свойство, известное как пересечение свойств (feature cross), позволяет модели обучаться отдельным весам для каждой комбинации свойств.
Конкретней, предположим мы хотим, чтобы наша модель вычисляла цены на недвижимость в Атланте. Цены на недвижимость в рамках города значительно различаются в зависимости от расположения. Представление широты и долготы отдельными свойствами не очень удобно для определения зависимости от расположения, однако, пересечение широты и долготы в единое свойство может указать расположение. Предположим мы представим Атланту как решетку из 100x100 квадратных участков, определяя каждый из 10000 участков пересечением свойств широты и долготы. Это пересечение свойств позволит модели тренироваться на ценовых условиях, относящихся к каждому участку, что является намного более эффективным методом, чем широта и долгота по отдельности.
Следующая иллюстрация показывает план, с значениями широты и долготы по углам города:

Карта Атланты. Представим эту карту, разделенной на 10000 участков одинакового размера.
Для решения, мы используем комбинацию bucketized_column, которую мы рассматривали выше, и tf.feature_column.crossed_column функции.
def make_dataset(latitude, longitude, labels):
assert latitude.shape == longitude.shape == labels.shape
features = {'latitude': latitude.flatten(),
'longitude': longitude.flatten()}
labels=labels.flatten()
return tf.data.Dataset.from_tensor_slices((features, labels))
# Пакетизируем широту и долготу, используя 'края'
latitude_bucket_fc = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column('latitude'),
list(atlanta.latitude.edges))
longitude_bucket_fc = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column('longitude'),
list(atlanta.longitude.edges))
# Создаем пересечения пакетизированных колонок,
# используя 5000 хэш ящиков.
crossed_lat_lon_fc = tf.feature_column.crossed_column(
[latitude_bucket_fc, longitude_bucket_fc], 5000)
fc = [
latitude_bucket_fc,
longitude_bucket_fc,
crossed_lat_lon_fc]
# Создаем и тренируем Estimator.
est = tf.estimator.LinearRegressor(fc, ...)
Мы можем создавать пересечения свойств по любому из следующего:
- Имена свойств; то есть имена из dict, возвращаемого из input_fn.
- Любая категориальная колонка, исключая categorical_column_with_hash_bucket (ввиду того что crossed_column хэширует ввод).
Когда колонки свойств latitude_bucket_fc и longitude_bucket_fc пересечены, TensorFlow создаст (latitude_fc, longitude_fc) пары для каждого примера. Это произведет полную таблицу возможных вариантов, как следующее:
(0,0), (0,1)... (0,99)
(1,0), (1,1)... (1,99)
... ... ...
(99,0), (99,1)...(99, 99)
За исключением случая, что полная таблица будет доступна только для вводов с ограниченными словарями. Вместо построения такой, потенциально большой таблицы вводов, crossed_column создает только количество, запрашиваемое hash_bucket_size аргументом. Колонка свойств назначает пример к индексу, выполняя хэш функцию на тапле вводов, следуемой операцией деления по модулю с hash_bucket_size.
Как обсуждалось ранее, выполнение хэш и модуль функций ограничивает количество категорий, но может вызвать коллизии категорий, то есть, несколько (широта, долгота) пересений свойств окажутся в одинаковом хэш ящике. На практике однако, выполнение пересечений свойств все равно дает значительную прибавку к обучаемой емкости модели.
Хотя это не очевидно, но при создании пересечений свойств, все равно требуется включать изначальные (непересеченные) свойства в модель (как в предыдущем отрезке кода). Независимые свойства широты и долготы помогают модели различать примеры, когда хэш коллизии случаются в пересечениях свойств.
Индикаторные и встроенные колонки (Indicator and embedding columns)
Индикаторные колонки и встроенные колонки никогда не работают на свойствах напрямую, но вместо этого принимают категориальные колонки как ввод.
Когда мы используем индикаторную колонку, мы говорим TensorFlow выполнять то, что мы видели в категориальном product_class примере. То есть, индикаторная колонка оценивает каждую категорию как элемент в одноразовом векторе, где соотвествующая категория имеет значение 1, а остальные имеют значение 0:
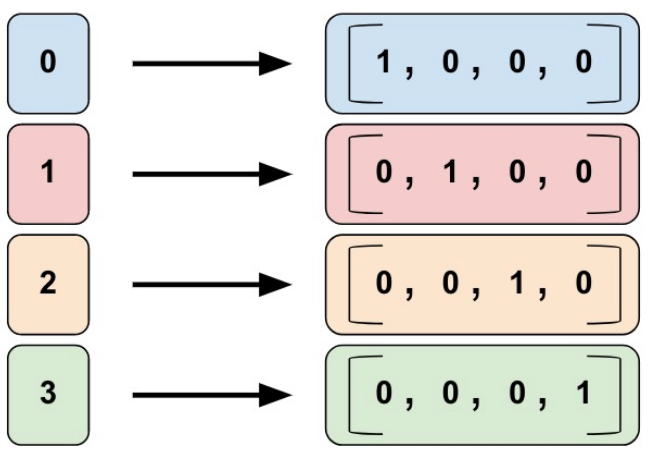
Представление данных в индикаторных колонках.
Вот как создавать индикаторную колонку, вызывая tf.feature_column.indicator_column:
categorical_column = ... # Создаем любой вид категориальной колонки.
# Представляем категориальную колонку как индикаторную колонку
indicator_column = tf.feature_column.indicator_column(
categorical_column)
Теперь предположим, что мы имеем не просто три возможных класса, а миллион возможных классов. Или миллиард. По ряду причин с ростом количества категорий становится невозможно тренировать нейронную сеть, используя индикаторные колонки.
Мы можем использовать встроенную колонку, чтобы обойти это ограничение. Вместо представления данных одноразовым вектором с многими измерениями встроенная колонка представляет данные как малоразмерный обыкновенный вектор, в котором каждое ячейка может содержать любое число, а не только 0 или 1. Разрешая большее разнообразие чисел для каждой ячейки, встроенная колонка содержит намного меньше ячеек, чем индикаторная колонка.
Взглянем на пример, сравнивающий индикаторные и встроенные колонки. Предположим вводные примеры состоят из различных слов из ограниченного набора 81 слова. Далее предположим, что набор данных предоставляет следующие вводные слова в 4 отдельных примерах:
- "dog"
- "spoon"
- "scissors"
- "guitar"
В этом случае следующая иллюстрация показывает путь обработки для встроенных колонок или индикаторных колонок.

Встроенная колонка сохраняет категориальные данные в векторе с меньшим количеством измерений, чем индикаторная колонка. (Мы просто разместим случайные числа в встроенных векторах; тренировка определяет актуальные числа.)
Когда пример орабатывается, одна из categorical_column_with... функций картирует строку примера к числовому категориальному свойству. Например, функция картирует "spoon" к [32]. (32 мы просто придумали - актуальное значение зависит от картирующей функции.) Затем можно представить эти числовые категориальные свойства любым из следующих способов:
- Как индикаторная колонка. Функция преобразует каждое числовое категориальное значение в 81-элементный вектор (поскольку мы ипользуем ограничение из 81 слова), размещая 1 для индекса категориального значения (0, 32, 79, 80) и 0 для всех остальных позиций.
- Как встроенная колонка. Функция использует числовые категориальные значения (0, 32, 79, 80) как индексы в поисковой таблице. Каждый слот в этой поисковой таблице состоит из 3-элементного вектора.
Как значения во встроенных векторах назначаются? На самом деле назначения происходят в ходе тренировки. То есть модель обучается наилучшему способу картировать вводные числовые категориальные значения к значению встроенного вектора, чтобы решить задачу. Встроенные колонки увеличивают возможности модели, ввиду того, что встроенный вектор обучается новым взаимоотношениям между категориями из тренировочных данных.
Почему встроенный вектор имеет размер 3 в нашем примере? Следующая "формула" предоставляет общее правило насчет количества измерений во встроенном векторе:
embedding_dimensions = number_of_categories**0.25
Ввиду того, что размер нашего словаря в этом примере 81, рекомендуемое количество измерений равно 3:
3 = 81**0.25
Отметим, что это только рекомендация, можно задавать количество встроенных измерений по своему желанию.
Вызываем tf.feature_column.embedding_column для создания embedding_column, как видно в следующем участке кода:
categorical_column = ... # Создаем любую категориальную колонку
# Представляем категориальную колонку как встроенную колонку.
# Это означает создание встроенного вектора поисковой таблицы
# с одним элементом для каждой категории.
embedding_column = tf.feature_column.embedding_column(
categorical_column=categorical_column,
dimension=embedding_dimensions)
Как показывает следующий список, не все Estimators принимают все типы колонок свойств.
- tf.estimator.LinearClassifier и tf.estimator.LinearRegressor: принимают все типы колонок свойств.
- tf.estimator.DNNClassifier и tf.estimator.DNNRegressor: только тесносвязанные (dense) колонки. Другие типы колонок должны быть обернуты в indicator_column или embedding_column.
- tf.estimator.DNNLinearCombinedClassifier и tf.estimator.DNNLinearCombinedRegressor:
- linear_feature_columns аргумент принимает любые типы колонок свойств.
- dnn_feature_columns принимают только тесносвязанные колонки.






