Многие задачи требуют вероятностной оценки как вывод. Логистическая регрессия - это крайне эффективный механизм для расчета вероятностей. Возвращаемую вероятность можно использовать любым из следующих способов:
- "Как есть"
- Преобразовать в бинарную категорию.
Посмотрим как мы можем использовать вероятность "Как есть". Предположим, мы создаем модель логистической регрессии, чтобы прогнозировать вероятность того, что собака будет лаять в середине ночи. Мы будем называть эту вероятность так:
p(bark | night)
Если модель логистической регрессии прогнозирует p(bark | night) равной 0.05, тогда в течение года владельцы собак должны быть испуганы приблизительно 18 раз:
startled = p(bark | night) * nights
18 ~= 0.05 * 365
Во многих случаях требуется картировать вывод логистической регрессии в решение проблемы бинарной классификации, в которой цель - корректно прогнозировать одну из двух возможных меток (например, спам или не спам).
Как может модель логистической регрессии обеспечивать вывод, который всегда попадает в промежуток между 0 и 1? Как оказывается, сигмоидная функция, определенная следующим образом, производит вывод, имеющий те же самые характеристики:

Сигмоидная функция выводит следующий график:
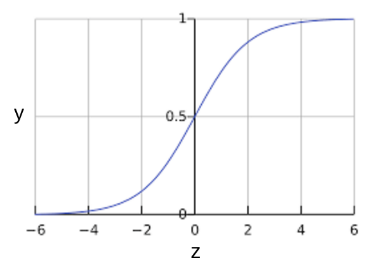
Сигмоидная функция
Если z представляет вывод линейного слоя модели, тренированной логистической регрессией, тогда функция sigmoid(z) будет выводить значение (вероятность) между 0 и 1. В математических терминах:

где:
- y' - это вывод модели логистической регрессии для отдельного примера
z равен b + w1x1 + w2x2 + ... wNxN
- w значения - это веса и смещения, которым обучилась модель
- x значения - это значения свойств для отдельного примера
Следует отметить, что z, также называют логарифмическими коэффициентами, потому что инверсия сигмоида констатирует, что z может быть определена как логарифм вероятности метки "1" (например, "собака лает") деленной на вероятность метки "0" (например, "собака не лает"):

Вот сигмоидная функция с метками машинного обучения:

Вывод логистической регрессии